Chapter 3: The data collection
In the following chapter we take care about the data collection, but first we need some basic information about what it's all about. Data collection is the process of systematically collecting, recording, and organizing information to be used in analysis, reporting, or decision-making. It can take various forms, including manual entry, automated sensors, surveys, or digital data storage. The quality of data collection is crucial as it forms the basis for accurate analysis and technical decisions. In today's data-driven world, data collection plays a central role in areas of research and enables trends to be identified and processes to be optimized. Completely in our spirit.
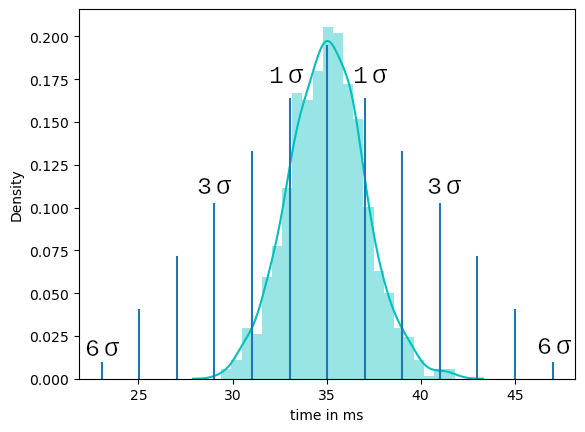
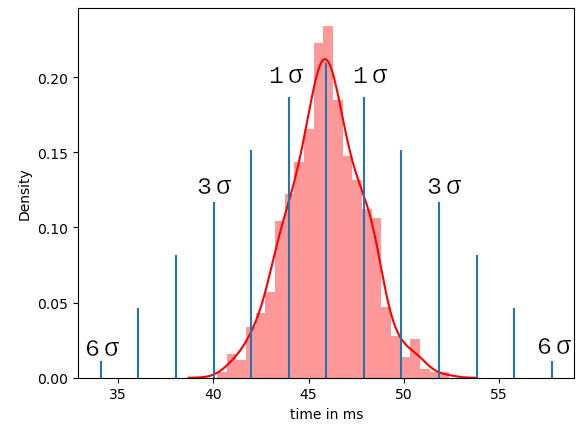
Let's get back to our example. We need to measure the delta between client request and server response to better understand how long a response takes. For better differentiation, we split the data collection into two individual measurements. The first data collected shows the response time under normal conditions. We then record a second series of measurements with a simulated stress operation in which we reprioritize some threads on the server device and add cpu intensive calculations. For those of you who do not have access to the server source code Interrupts are also quite suitable to stress the cpu..Or you can try to simulate a high data load on another communication interface by sending a large amount of data via the another interface. There are tons of different approaches to stress a system, which unfortunately I cannot fully address in this article. But just as a hint there are numerous software tools on the market which can help you to utilize system capacity. But sometimes. There are various options available.
The following trace shows you an example how the device behaves under normal conditions. For the measurement I use a CH340 usb adapter and a self-written trace tool, which works quite easily under Linux and calculates the time delta at the same time if the header of the message is a duplicate the previous one. Are you using Windows or Mac? There are tons of good analysis tools available for free. Since the formatting of these tools always varies quite a bit, it is a good idea to post-process the data before further analysis. I do not cover this point in this article but you can reach out to me in case you need some assistance.
Side Note:
I personally work a lot with the python package “pandas”. This makes it easy to analyze the data series with a little practice. The data used here looks like this:
13:24:02:4162, 0x03 0x02 0x00 0xc4 0x00 0x16 0xba 0xa9 || CRC: correct
13:24:02:4483, 0x03 0x02 0x03 0xac 0xbd 0x35 0x20 0x18 || CRC: correct
>> delta 32,1 ms
You can save the follwowing data *.csv file and do the same calcaulation with the function shown in chapter 4
30.5,34.4,32.9,32.0,36.5,34.1
,35.5,35.2,35.0,33.7,35.4,33.4
,34.9,37.9,33.7,33.9,34.1,35.3
,35.0,35.8,33.8,34.8,30.3,38.8
,34.6,32.9,34.8,33.3,35.3,30.9
,36.2,35.0,30.2,36.6,39.5,33.3
,35.0,38.6,33.6,33.7,33.9,37.0
,37.8,32.9,37.8,33.7,35.0,32.8
,37.9,35.1,35.9,35.9,34.8,37.7
,32.7,33.0,36.2,35.9,30.6,33.5
,34.4,32.4,35.4,37.6,35.4,34.6