Kapitel 3: Die Datenerfassung
Im folgendem etwas Theorie zur Datenerfassung. Die Datenerfassung ist der Prozess, bei dem Informationen systematisch gesammelt, aufgezeichnet und organisiert werden, um sie für Analysen, Berichte oder Entscheidungsfindungen zu nutzen. Sie kann in verschiedenen Formen erfolgen, darunter manuelle Eingabe, automatisierte Sensoren, Umfragen oder digitale Datenspeicherung. Die Qualität der Datenerfassung ist entscheidend, da sie die Grundlage für präzise Analysen und fundierte Entscheidungen bildet. In der heutigen datengetriebenen Welt spielt die Datenerfassung eine zentrale Rolle in Bereichen der Forschung und ermöglicht, Trends zu erkennen und Prozesse zu optimieren. Ganz in unserem Sinne also.
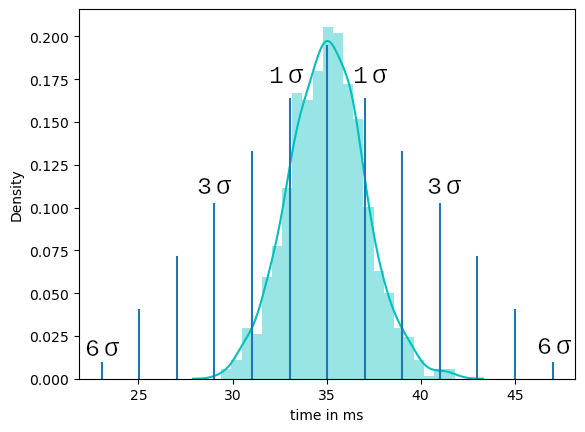
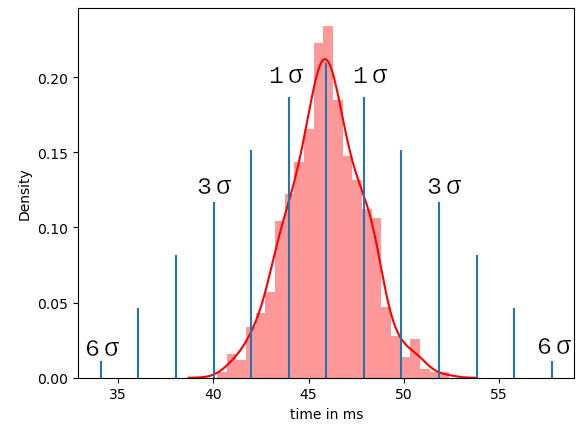
Für unser Beispiel messen wir also das Delta zwischen Client Request und Server Response. Zur besseren Differenzierung teilen wir die Datenerfassung in zwei Messungen auf. Die hier gesammelten Daten zeigen zunächst die Antwortzeit im Normalbetrieb. Anschließend nehmen wir eine zweite Messreihe auf mit einem simulierten Stress-Betrieb in dem wir beim Server einige Threads umpriorisieren und Art Dauerberechnungen hinzufügen und den Prozessor auslasten. Interrupts eignen sich an dieser Stelle auch recht gut. Bei Geräten in deinem Kommunikationsnetzwerk, auf die du keinen direkten Zugriff auf den Quellcode hast, wird es durchaus schwieriger. An dieser Stelle kann man zum Beispiel auf einer anderen Kommunikationsschnittstelle eine hohe Datenlast simulieren, indem man hohe Datenmengen über die entsprechende Schnittstelle schickt. Hierzu gibt es massenhaft verschiedene Herangehensweisen, auf die ich leider nicht in vollem Umfang in diesem Artikel eingehen kann. Darüber hinaus gibt es zahlreiche Software-Tools, die euch helfen können, System auszulasten. Aber manchmal reicht es auch schon, große Datenmengen über das Terminal zu schicken, um den besagten Effekt zu erzielen. Hier sind der Kreativität keine Grenzen gesetzt.
Der folgende Trace zeigt uns ein Beispiel aus dem Normalbetrieb zur besseren Vorstellung. Für die Messung benutze ich einen CH340 usb Adapter und ein selbstgeschriebenes Trace-Tool, was unter Linux recht einfach funktioniert und gleichzeitig das zeitliche Delta berechnet. Du benutzt Windows oder Mac? Auch hier gibt es massenhaft frei verfügbare Analyse-Tools. Da die Formatierung dieser Tools immer recht stark variiert, biete es sich an die Daten im so genannten post processing für unsere weitere Analyse aufzubereiten. Dies setze ich an dieser Stelle als gegeben voraus, da ich sonst den Rahmen des eigentlichen Themas sprenge.
Side Note:
Schau dir mal das Python Paket pandas genauer an. Hiermit ist eine Analyse der Datenreihe problemlos mit etwas Übung möglich. Wichtig ist nur, dass ihr das zeitliche Delta zwischen request und response vorliegen habt. Die hier verwendeten Daten sehen so aus und sind im csv Datei Format gespeichert:
13:24:02:4162, 0x03 0x02 0x00 0xc4 0x00 0x16 0xba 0xa9 || CRC: correct
13:24:02:4483, 0x03 0x02 0x03 0xac 0xbd 0x35 0x20 0x18 || CRC: correct
>> delta 32,1 ms
Du kannst die folgenden Daten als *.csv Datei abespeichern und dann mit dem in Kapitel 4 gezeigten Code auswerten:
30.5,34.4,32.9,32.0,36.5,34.1
,35.5,35.2,35.0,33.7,35.4,33.4
,34.9,37.9,33.7,33.9,34.1,35.3
,35.0,35.8,33.8,34.8,30.3,38.8
,34.6,32.9,34.8,33.3,35.3,30.9
,36.2,35.0,30.2,36.6,39.5,33.3
,35.0,38.6,33.6,33.7,33.9,37.0
,37.8,32.9,37.8,33.7,35.0,32.8
,37.9,35.1,35.9,35.9,34.8,37.7
,32.7,33.0,36.2,35.9,30.6,33.5
,34.4,32.4,35.4,37.6,35.4,34.6