Warum ein while(1) im HardFault_Handler fahrlässig ist und wie man den Fehler ohne Debugger findet. Wir kennen das Szenario: Das Gerät beim Kunden friert ein. Keine LED blinkt mehr. Totenstille. Ein Reset hilft – bis zum nächsten Mal. Ohne Debugger stehen viele Teams hier im Dunkeln. Dabei liefert uns der ARM Cortex-M Kern alles, was wir zur Diagnose brauchen, frei Haus – wir müssen nur hinsehen. Viele Standard-Projekte (gerade die von Code-Generatoren) implementieren den HardFault_Handler einfach als while(1). Das ist im Labor okay, im Feld aber eine Katastrophe.
💡 Mein Ansatz für schnelles Troubleshooting:
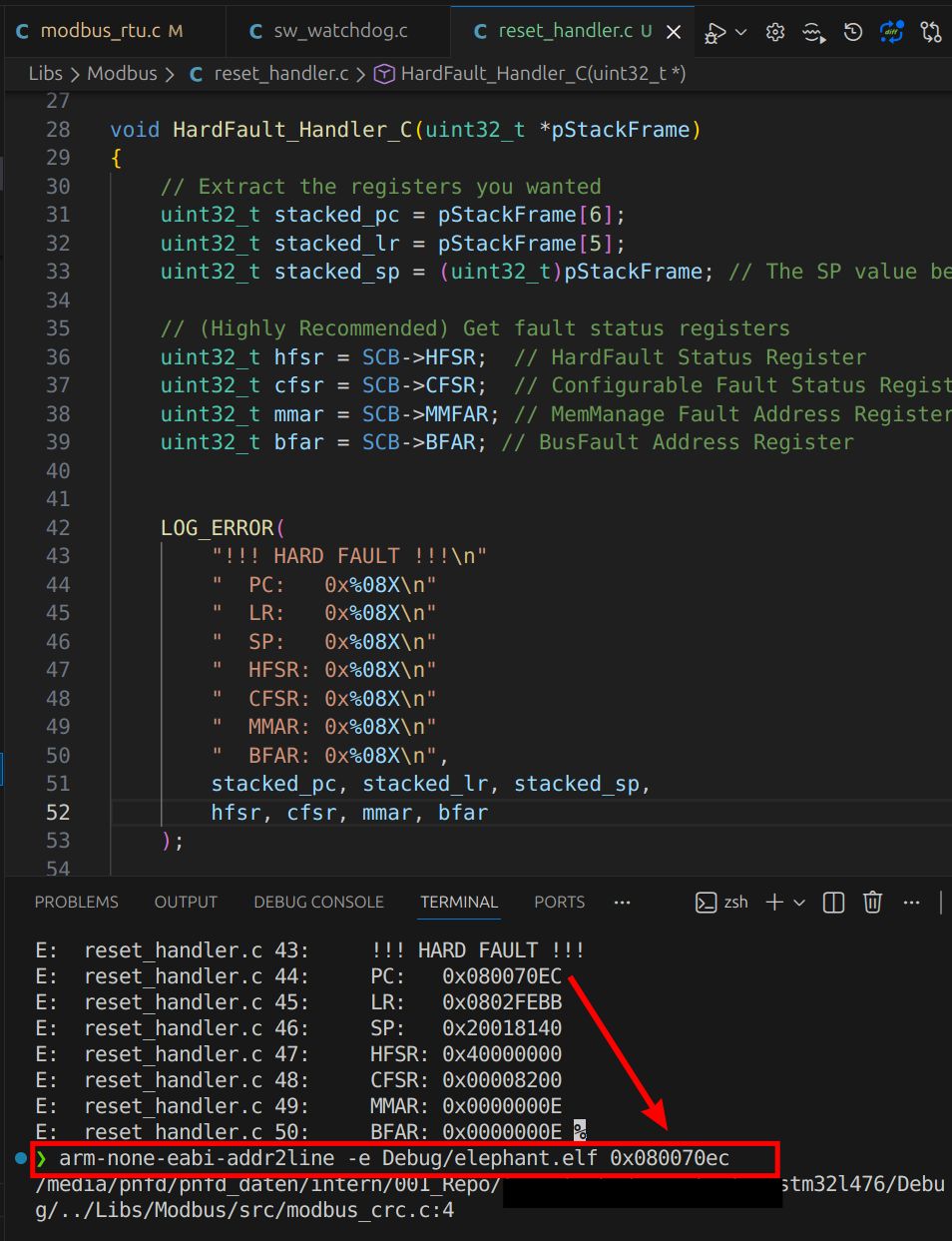
Wenn der Cortex-M in den HardFault springt, pusht er automatisch einen "Stack Frame" auf den Stack. Darin enthalten: R0-R3, R12, LR, xPSR und – das Wichtigste – der Program Counter (PC) zum Zeitpunkt des Absturzes.Anstatt nur in einer Endlosschleife zu hängen, lese ich diesen PC-Wert aus (und speichere ihn z.B. im EEPROM, .noinit area oder gebe ihn auf der UART aus (das klappt nicht immer - trust me ...).
🔧 Der "Magic Trick" mit der ELF-Datei:
Haben wir die Adresse (z.B. 0x080070EC), brauchen wir keinen teuren Trace-Debugger, um den Übeltäter zu finden. Ein einfaches Tool aus der GNU Toolchain reicht:
arm-none-eabi-addr2line -e firmware.elf 0x080070EC../Libs/Modbus/src/modbus_crc.c:40Und schon wissen wir: Es war der Dereferenzierungs-Fehler in Zeile 40. Keine Magie, nur solides Verständnis der Architektur.
Zurück zur Übersicht